




Protection pratique du site Web contre les robots IA, car robots.txt n'est pas suffisant
Pourquoi est-ce important: Il existe un consensus croissant sur le fait que l'IA générative a le potentiel de rendre le Web ouvert bien pire qu'il ne l'était auparavant. Actuellement, toutes les grandes entreprises technologiques et les startups d'IA comptent sur la récupération de tout le contenu original qu'elles peuvent sur le Web pour entraîner leurs modèles d'IA. Le problème est qu'une écrasante majorité des sites Web ne sont pas d'accord avec cela, et n'ont pas donné leur autorisation pour cela. Mais bon, demandez simplement au PDG de Microsoft AI, qui pense que le contenu du Web ouvert est un « logiciel gratuit ».
La semaine dernière, un rapport d’Akamai a reconfirmé que les robots représentent une part énorme du trafic Web global et que l’IA facilite grandement la tâche des cybercriminels et des entreprises malhonnêtes.
Les sites Web et les créateurs de contenu utilisant les services de diffusion de contenu et de pare-feu fournis par Cloudflare disposent désormais d'une solution supplémentaire et facile à utiliser pour limiter la capacité des Big Tech à libérer leurs robots et à extraire du contenu Web sans autorisation explicite.

Les entreprises d’IA les plus connues, comme OpenAI, ont commencé à proposer un moyen de bloquer leurs robots d’exploration grâce à des règles personnalisées qui peuvent être ajoutées à un fichier robots.txt sur le serveur. Cependant, ces solutions ne fonctionnent que lorsque le robot a été conçu pour suivre réellement ces règles. Le problème est que 1) toutes les entreprises ne sont pas disposées à respecter les directives du fichier robots.txt et 2) de nombreuses entreprises d’IA ont déjà tout abandonné avant de proposer cette option de « désactivation ». Cloudflare affirme qu’une écrasante majorité de ses clients, jusqu’à 85 %, ont déjà choisi de bloquer les robots d’IA de cette manière.
La nouvelle solution en un clic proposée par Cloudflare est disponible pour les clients gratuits et payants, et semble être capable de lutter efficacement contre les robots IA qui ne respectent pas les règles du fichier robots.txt. Cloudflare peut identifier les robots et créer des empreintes digitales individuelles pour chacun d'eux, et s'engage à mettre à jour automatiquement sa base de données d'empreintes digitales au fil du temps.
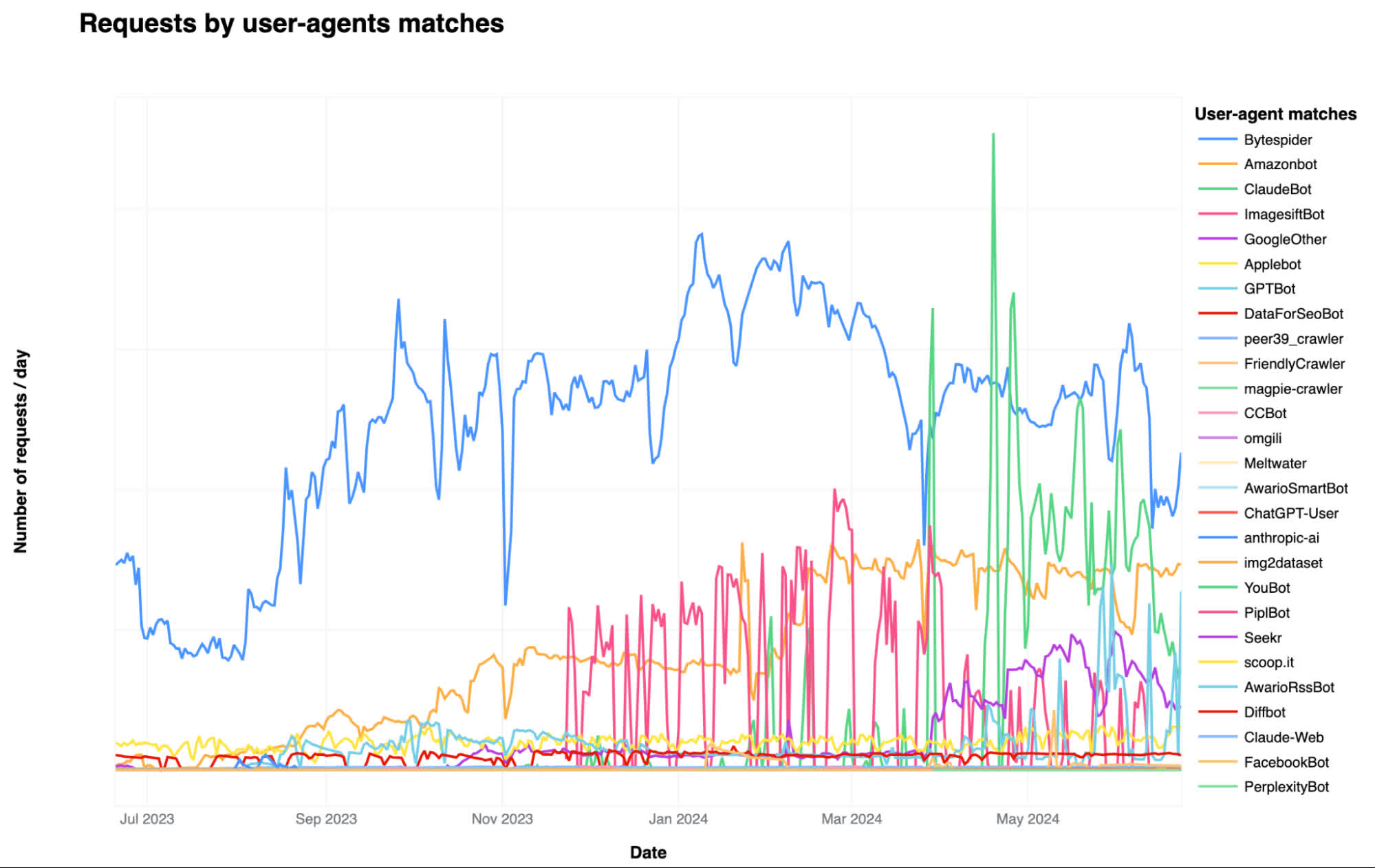
En tant que l’un des plus grands réseaux CDN sur Internet, Cloudflare peut extrapoler les données de plus de 57 millions de requêtes réseau par seconde en moyenne.
L'entreprise a dressé une liste des robots d'intelligence artificielle les plus actifs qui pillent le Web d'aujourd'hui, Bytespider, GPTBot et ClaudeBot étant les trois plus importants en termes de part de sites Web consultés. Bytespider est exploité par la société chinoise ByteDance, propriétaire de TikTok, et utilise probablement le contenu récupéré sur 40 % des sites Web protégés par Cloudflare pour former ses grands modèles linguistiques.
GPTBot accède à 35 % des sites Web et collecte des données pour former ChatGPT et d'autres services d'IA générative proposés par OpenAI. ClaudeBot a récemment augmenté son volume de requêtes jusqu'à 11 %, selon Cloudflare, et est utilisé pour former la famille d'algorithmes LLM du même nom développée par Anthropic.
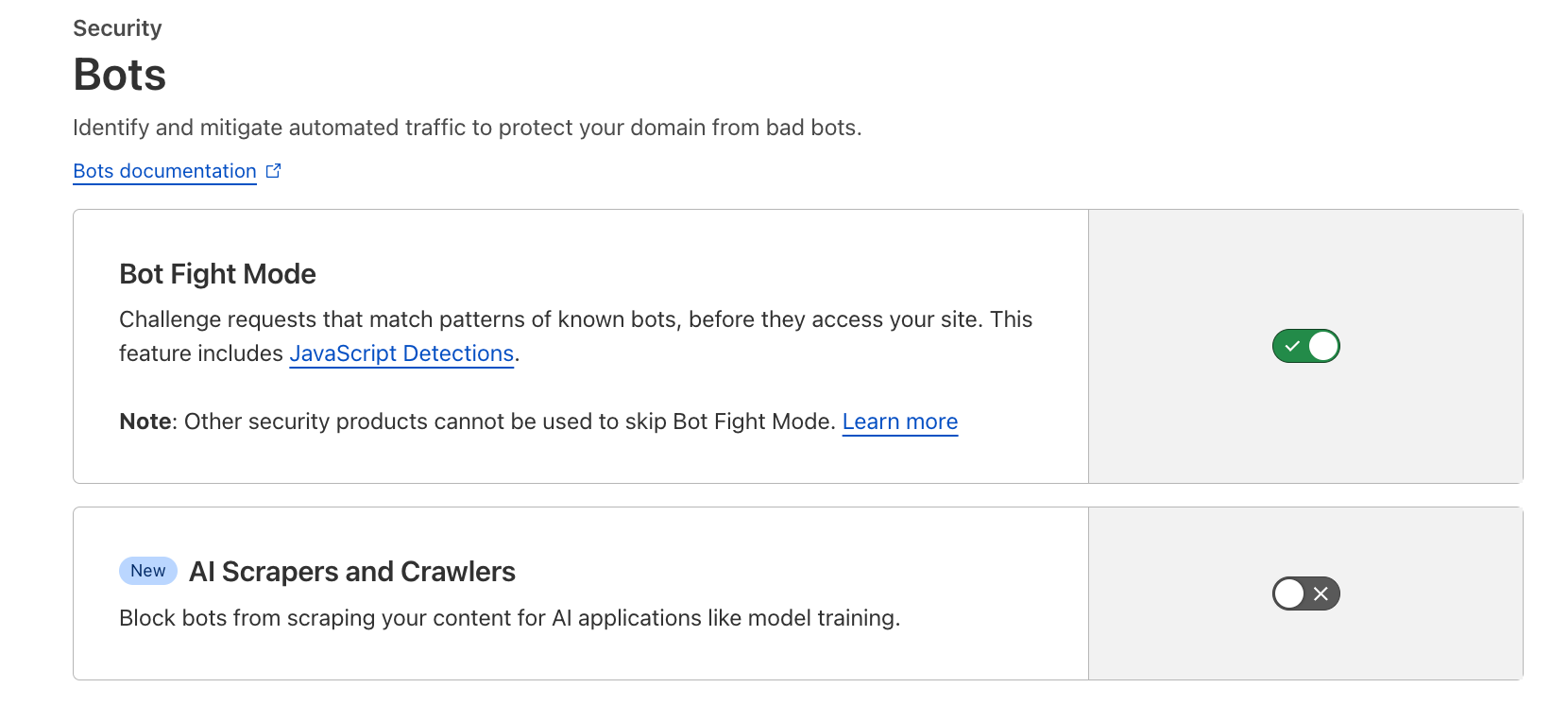
Bien que ces robots bien connus devraient être plus faciles à identifier grâce à un effort d’analyse statique, Cloudflare peut également détecter des robots se faisant passer pour de vraies personnes naviguant sur le Web.
L'entreprise a développé son propre modèle mondial d'apprentissage automatique et utilise essentiellement la technologie de l'IA pour reconnaître les robots IA se faisant passer pour autre chose. Cloudflare a déclaré que son modèle était capable de « signaler de manière appropriée le trafic » provenant de robots IA évasifs, et qu'il sera utilisé pour détecter de nouveaux outils de scraping et de faux robots à l'avenir sans avoir besoin de générer au préalable une nouvelle empreinte digitale de robot.