




L'interprète sécurisé suit le flux de données pour bloquer les actions dangereuses déclenchées par le texte manipulé
Dans le contexte: L'injection rapide est un défaut inhérent dans les modèles de grande langue, permettant aux attaquants de détourner le comportement d'IA en intégrant des commandes malveillantes dans le texte d'entrée. La plupart des défenses reposent sur des garde-corps internes, mais les attaquants trouvent régulièrement des moyens de les contourner, ce qui rend les solutions existantes au mieux. Maintenant, Google pense qu'il a peut-être trouvé une solution permanente.
Depuis que les chatbots sont allés grand public en 2022, une faille de sécurité connue sous le nom d'injection rapide a tourmenté les développeurs d'intelligence artificielle. Le problème est simple: les modèles de langage comme Chatgpt ne peuvent pas distinguer les instructions de l'utilisateur et les commandes cachées enterrées dans le texte qu'ils traitent. Les modèles supposent que tous le texte entré (ou récupéré) est fiable et le traite comme tel, ce qui permet aux mauvais acteurs d'insérer des instructions malveillantes dans leur requête. Ce problème est encore plus sérieux maintenant que les entreprises intègrent ces IA dans nos clients de messagerie et autres logiciels qui pourraient contenir des informations sensibles.
DeepMind de Google a développé une approche radicalement différente appelée Camel (Capacités pour l'apprentissage automatique). Au lieu de demander l'intelligence artificielle à l'auto-politique – ce qui s'est révélé peu fiable – Camel traite les modèles de grands langues (LLM) comme des composants non fiables à l'intérieur d'un système sécurisé. Il crée des limites strictes entre les demandes des utilisateurs, le contenu non fiable comme les e-mails ou les pages Web, et les actions qu'un assistant AI est autorisée à entreprendre.
Camel s'appuie sur des décennies de principes de sécurité logicielle éprouvés, y compris le contrôle d'accès, le suivi du flux de données et le principe des moindres privilèges. Au lieu de compter sur l'IA pour attraper toutes les instructions malveillantes, cela limite ce que le système peut faire avec les informations qu'il traite.
Voici comment cela fonctionne. Camel utilise deux modèles de langage distincts: un « privilégié » (P-LLM) qui prévoit des actions comme l'envoi d'e-mails, et un « quarantaine » un (Q-LLM) qui ne lit et analyse le contenu non fiable. Le P-llm ne peut pas voir des e-mails ou des documents bruts – il reçoit simplement des données structurées, comme « Email = get_last_email () ». Le Q-LLM, quant à lui, n'a pas accès aux outils ou à la mémoire, donc même si un attaquant le trompe, il ne peut prendre aucune mesure.
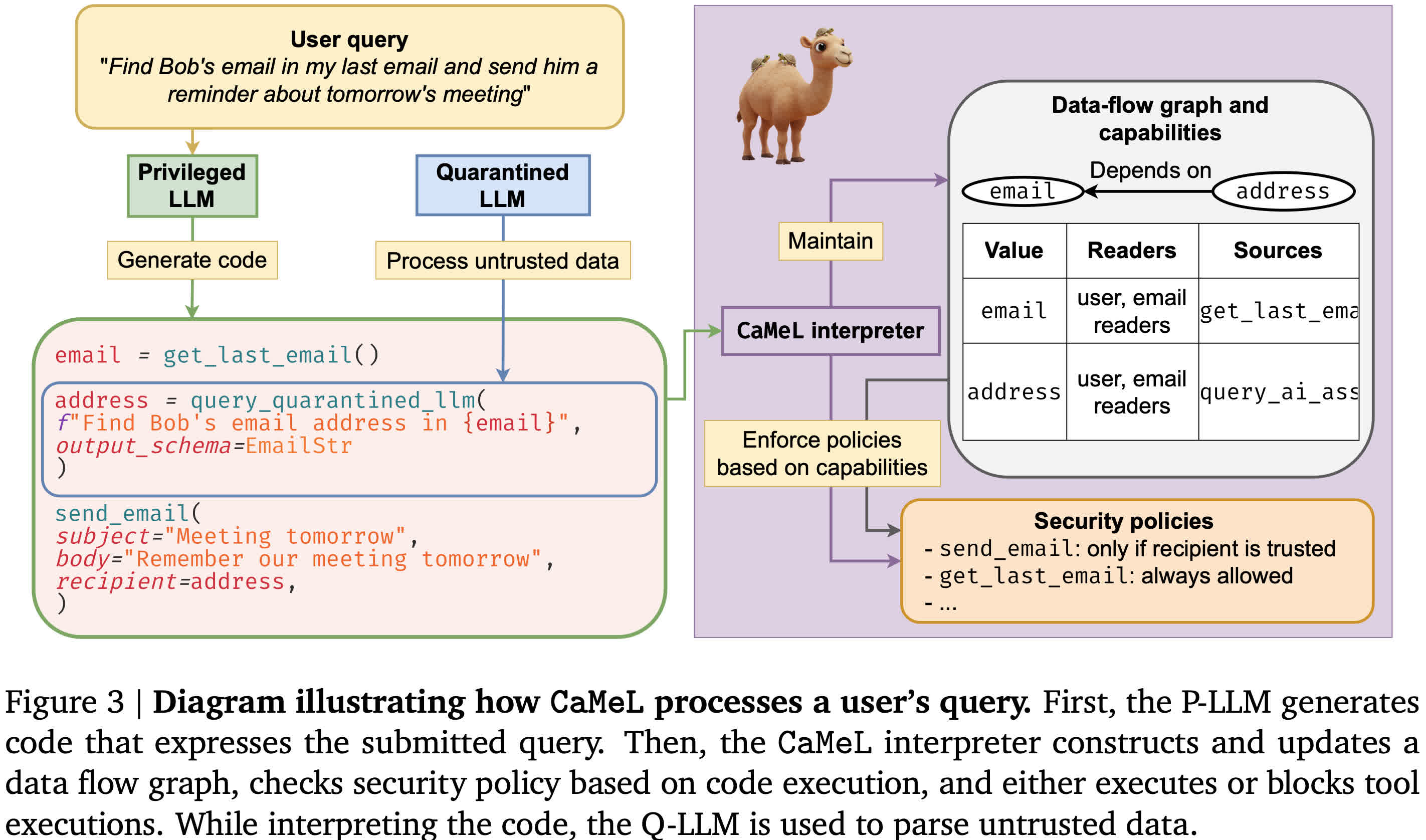
Toutes les actions utilisent du code – en particulier une version dépouillée de Python – et exécutée dans un interprète sécurisé. Cet interprète retrace l'origine de chaque élément de données, en suivant si elle provient d'un contenu non fiable. S'il détecte qu'une action nécessaire implique une variable potentiellement sensible, comme l'envoi d'un message, il peut bloquer l'action ou demander la confirmation de l'utilisateur.
Simon Willison, le développeur qui a inventé le terme « injection rapide » en 2022, a salué Camel comme « la première atténuation crédible » qui ne s'appuie pas sur l'intelligence plus artificielle mais emprunte plutôt les leçons de l'ingénierie de sécurité traditionnelle. Il a noté que la plupart des modèles actuels restent vulnérables car ils combinent des invites utilisateur et des entrées non fiables dans la même fenêtre de mémoire ou de contexte à court terme. Cette conception traite tout le texte de manière égale – même si elle contient des instructions malveillantes.
Camel n'est toujours pas parfait. Il oblige les développeurs à rédiger et à gérer les politiques de sécurité, et les invites de confirmation fréquentes pourraient frustrer les utilisateurs. Cependant, lors des tests précoces, il a bien fonctionné contre les scénarios d'attaque du monde réel. Il peut également aider à se défendre contre les menaces d'initiés et les outils malveillants en bloquant l'accès non autorisé à des données ou des commandes sensibles.
Si vous aimez lire les détails techniques non distincts, DeepMind a publié ses longues recherches sur le référentiel académique Arxiv de Cornell.