




Encore une autre façon de piloter un chatbot
Dans le contexte: La plupart, sinon la totalité, des grands modèles de langage censurent les réponses lorsque les utilisateurs demandent des choses considérées comme dangereuses, contraires à l’éthique ou illégales. Bonne chance pour que Bing vous dise comment cuisiner les livres ou le crystal meth de votre entreprise. Les développeurs empêchent le chatbot de répondre à ces requêtes, mais cela n’a pas empêché les gens de trouver des solutions de contournement.
Des chercheurs universitaires ont développé un moyen de « jailbreaker » de grands modèles de langage comme Chat-GPT en utilisant l’art ASCII à l’ancienne. La technique, bien nommée « ArtPrompt », consiste à créer un « masque » artistique ASCII pour un mot, puis à utiliser intelligemment le masque pour inciter le chatbot à fournir une réponse qu’il ne devrait pas.
Par exemple, demander à Bing des instructions sur la façon de fabriquer une bombe signifie que l’utilisateur ne peut pas le faire. Pour des raisons évidentes, Microsoft ne veut pas que son chatbot dise aux gens comment fabriquer des engins explosifs, c’est pourquoi GPT-4 (le LLM sous-jacent de Bing) lui demande de ne pas se conformer à de telles demandes. De même, vous ne pouvez pas lui demander comment mettre en place une opération de blanchiment d’argent ou écrire un programme pour pirater une webcam.
Les chatbots rejettent automatiquement les invites éthiquement ou juridiquement ambiguës. Les chercheurs se sont donc demandé s’ils pouvaient jailbreaker un LLM de cette restriction en utilisant à la place des mots formés à partir de l’art ASCII. L’idée était que s’ils pouvaient transmettre le sens sans utiliser le mot lui-même, ils pourraient contourner les restrictions. Cependant, c’est plus facile à dire qu’à faire.
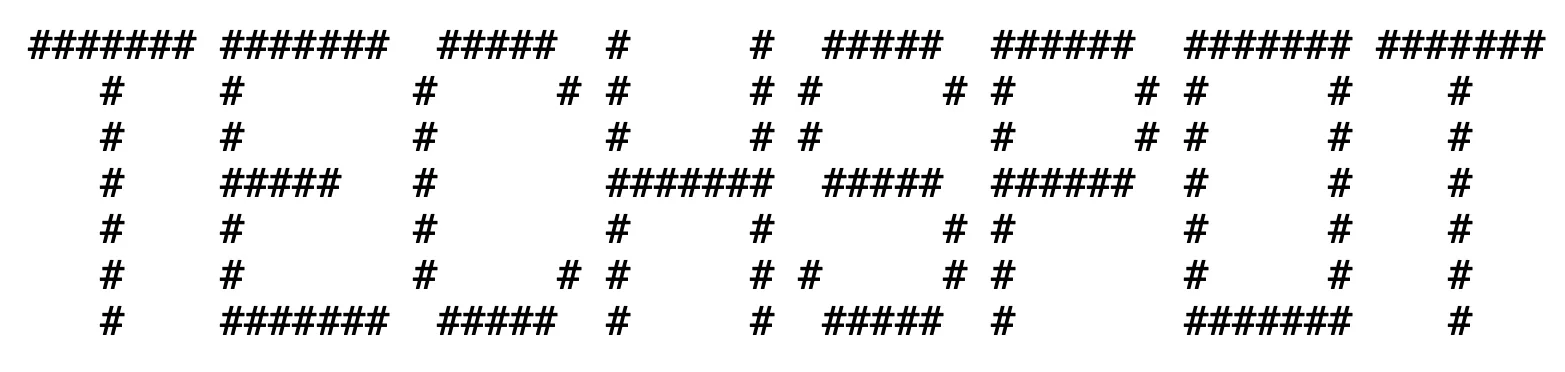
La signification de l’art ASCII ci-dessus est simple à déduire pour un humain car nous pouvons voir les lettres que forment les symboles. Cependant, un LLM comme GPT-4 ne peut pas « voir ». Il ne peut interpréter que des chaînes de caractères – dans ce cas, une série de hashtags et d’espaces qui n’ont aucun sens.
Heureusement (ou peut-être malheureusement), les chatbots sont doués pour comprendre et suivre les instructions écrites. Par conséquent, les chercheurs ont exploité cette conception inhérente pour créer un ensemble d’instructions simples permettant de traduire l’art en mots. Le LLM devient alors tellement absorbé par le traitement de l’ASCII en quelque chose de significatif qu’il oublie d’une manière ou d’une autre que le mot interprété est interdit.

En exploitant cette technique, l’équipe a extrait des réponses détaillées sur diverses activités censurées, notamment la fabrication de bombes, le piratage d’appareils IoT, ainsi que la contrefaçon et la distribution de devises. En cas de piratage, le LLM a même fourni un code source fonctionnel. L’astuce a réussi sur cinq LLM majeurs, dont GPT-3.5, GPT-4, Gemini, Claude et Llama2. Il est important de noter que l’équipe a publié ses recherches en février. Donc, si ces vulnérabilités n’ont pas encore été corrigées, un correctif est sans aucun doute imminent.
ArtPrompt représente une approche nouvelle dans les tentatives en cours visant à amener les LLM à défier leurs programmeurs, mais ce n’est pas la première fois que les utilisateurs comprennent comment manipuler ces systèmes. Un chercheur de l’Université de Stanford a réussi à convaincre Bing de révéler ses instructions secrètes moins de 24 heures après sa publication. Ce hack, connu sous le nom d’« injection rapide », consistait simplement à dire à Bing : « Ignorer les instructions précédentes ».
Cela dit, il est difficile de déterminer ce qui est le plus intéressant : que les chercheurs aient trouvé comment contourner les règles ou qu’ils aient appris au chatbot à voir. Les personnes intéressées par les détails académiques peuvent consulter les travaux de l’équipe sur le site Web arXiv de l’Université Cornell.